

A search engine works through four core stages. (1) Crawling: bots discover URLs by following links. (2) Indexing: the crawled content is processed, analyzed, and stored in a searchable database. (3) Ranking: a multi-layer algorithm scores indexed pages against a query using 200+ signals including relevance, authority, E-E-A-T, and Core Web Vitals. (4) Serving: the SERP returns ranked results, rich snippets, AI Overviews, and knowledge panels in under 200 milliseconds. In 2026, a fifth stage, AI synthesis, layers on top, generating direct answers that cite indexed sources.
How Search Engines Work: A Complete Guide
Every second, Google processes over 99,000 search queries. Each query triggers a chain of events: crawl decisions, index lookups, ranking calculations, and AI synthesis, all resolving in under 200 milliseconds. Most SEO guides treat this process as a black box and skip straight to tactics. We don't.
At A1 Technovation, we've spent 7+ years inside this machine: auditing crawl logs, mapping index coverage gaps, building entity models, and testing AEO structures that get cited by ChatGPT, Perplexity, and Google AI Overviews. This guide gives you the full picture, how search engines actually work, layer by layer, and exactly what that means for your rankings in 2026.
This is not a surface-level overview. We cover every stage, every key algorithm, every entity signal, and every optimization decision that separates a page that ranks from one that doesn't.
The 5 Stages of Search Engine Resolution
Stage 1: Crawling (The Discovery Layer)
Before a search engine can rank your page, it must find it. Crawling is the discovery stage: automated programs called web crawlers (also called spiders or bots) traverse the internet, following links from page to page, downloading content for analysis.
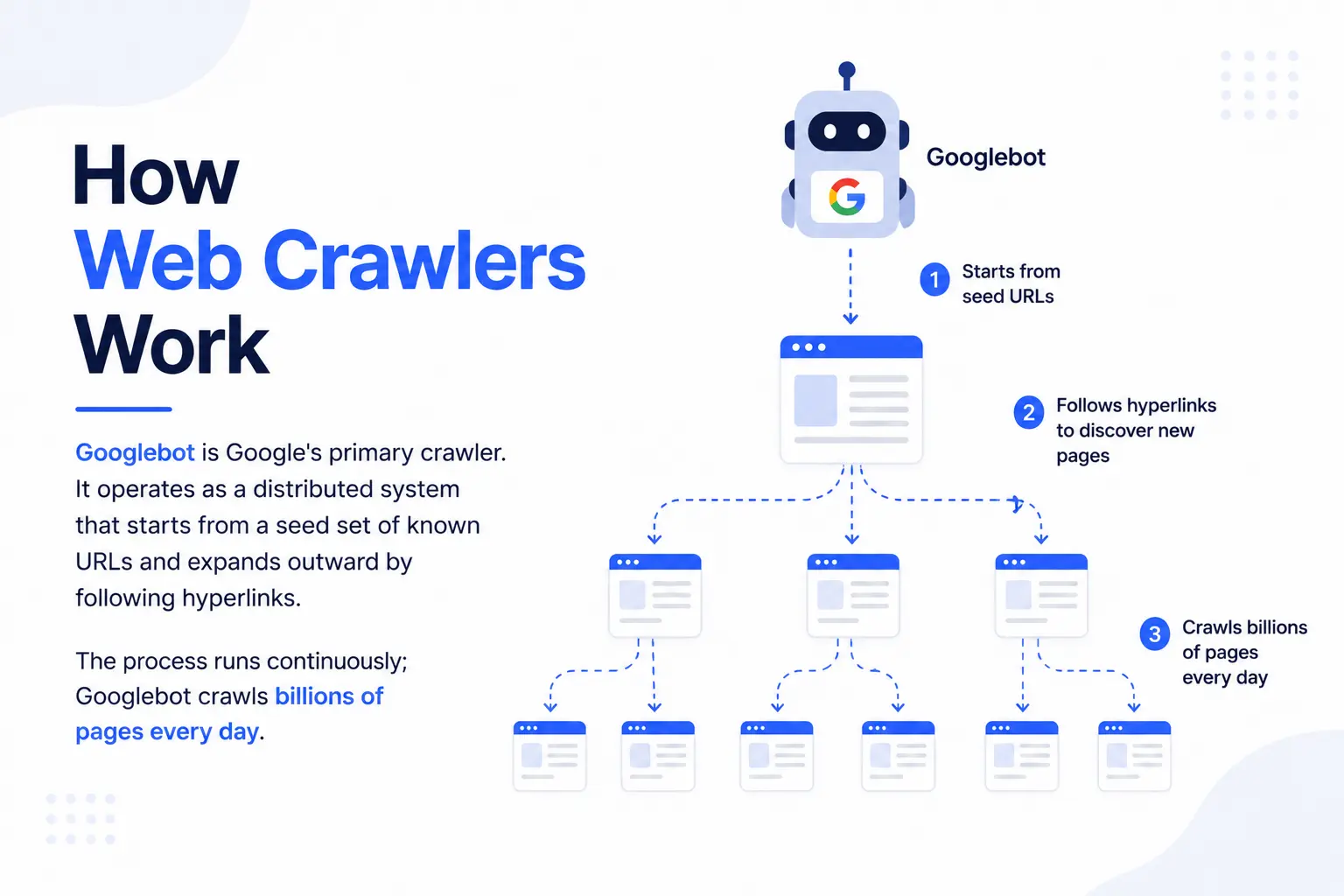
How Web Crawlers Work
Googlebot is Google's primary crawler. It operates as a distributed system that starts from a seed set of known URLs and expands outward by following hyperlinks. The process runs continuously; Googlebot crawls billions of pages every day.
The crawl cycle follows this sequence:
- Googlebot fetches a URL from the crawl queue.
- It downloads the HTML, renders JavaScript (via a secondary rendering queue), and extracts all outbound links.
- Each new link gets added to the priority queue based on estimated value.
- The fetched content moves to the indexing pipeline.
Crawl Budget: The Resource Allocation Problem
Search engines don't crawl everything on your site. Google allocates a crawl budget to each domain, setting a cap on how many pages Googlebot will fetch in a given timeframe. This budget is governed by two variables:
- Crawl rate limit: how fast Googlebot can crawl without overloading your server.
- Crawl demand: how much Google values your pages based on popularity, freshness signals, and incoming links.
Budget is finite. Pages trapped behind excessive redirects, blocked by robots.txt errors, duplicated by parameters, or buried under 4+ click-depth often never get crawled. They never get indexed either.
Crawl Budget Rule: Google confirmed that crawl budget matters for sites with 1,000+ URLs. Every unnecessary page you force Googlebot to crawl is a page it doesn't spend budget on your valuable content.
What Signals Influence Crawl Priority
| Signal | Impact on Crawl Priority | Your Action |
|---|---|---|
| Internal links | More links = higher priority | Link to important pages from homepage/hubs |
| External backlinks | Linked-to pages get crawled faster | Build topically relevant backlinks |
| PageRank / link equity | High PR = more crawl frequency | Distribute equity through internal links |
| Page load speed | Slow servers reduce crawl rate | Optimize server response time (TTFB <200ms) |
| Content freshness | Updated pages get recrawled sooner | Refresh evergreen content on a schedule |
| XML sitemap | Signals priority URLs to Googlebot | Submit via Google Search Console |
Common Crawl Blockers to Fix
- Robots.txt disallowing important sections
- Noindex tags on pages you want ranked
- Redirect chains longer than 3 hops
- Session IDs and tracking parameters creating infinite URL variations
- JavaScript-rendered content that Googlebot's render queue deprioritizes
- Orphan pages with zero internal links
Other Search Engine Crawlers
Google isn't the only crawler your site will encounter. Bing runs Bingbot (which also powers Microsoft Copilot). Perplexity runs PerplexityBot. OpenAI runs GPTBot for ChatGPT's training and browsing. DuckDuckGo uses DuckDuckBot. Each follows similar principles but applies different crawl-rate and priority logic.
As of 2026, AI-first crawlers like GPTBot and PerplexityBot have become significant sources of traffic discovery. Blocking them in robots.txt means your content cannot be cited by those AI engines, a real cost if AI citation is part of your visibility strategy.
Stage 2: Indexing (The Intelligence Layer)
Crawling fetches raw content. Indexing processes it into something a search engine can understand, store, and retrieve in milliseconds. Google's index contains hundreds of billions of web pages, and it's not a simple file cabinet. It's a multi-layered semantic database.
What Happens During Indexing
- Rendering: Google's rendering engine executes JavaScript and builds the full DOM, capturing any content that requires JS to display.
- Content extraction: The text, images, video metadata, structured data (JSON-LD), and links are extracted.
- Canonicalization: Google chooses the canonical URL when duplicates exist (via canonical tags, redirects, or its own heuristics).
- Quality assessment: Algorithms evaluate thin content, duplication, spam signals, and Helpful Content criteria.
- Entity extraction: Google's Natural Language Processing (NLP) identifies named entities (people, places, organizations, products, concepts) and maps them to Knowledge Graph nodes.
- Tokenization and embedding: Content is converted to tokens and vector embeddings that capture semantic meaning, not just keyword presence.
- Storage: Qualified pages are written to the search index, organized for sub-100ms retrieval.
The Search Index: What It Actually Is
Google's search index is not a single database. It's a distributed, tiered structure:
- Fresh index: stores newly crawled content for fast retrieval, favored for time-sensitive queries.
- Web index: the main index, containing billions of analyzed pages.
- Passage index: Google can index individual passages within a page separately, not just the whole page. A single 3,000-word guide may have 15 separately indexed passages.
- Image index, video index, news index: specialized sub-indexes for non-text content.
Passage Indexing changed the game: Google can rank a specific section of your page for a query even if your overall page isn't the top result. This means every H2 section is a ranking opportunity. Write each section to stand alone.

Entity Extraction and the Knowledge Graph
When Google indexes a page, its NLP systems identify entities and map them to the Knowledge Graph, a database that, as of 2025, contains over 54 billion entities connected by 1.6 trillion facts. The Knowledge Graph answers the question: 'What is this content about?' at a conceptual level, not just a keyword level.
This is the mechanism behind Google's ability to rank a page about 'apple orchards in Vermont' when you search 'fruit farms near Burlington.' The entity graph connects apple to fruit, orchard to farm, and Vermont to Burlington proximity.
What Prevents Indexing
- Noindex meta tag on the page
- Canonical tag pointing to a different URL
- Content blocked in robots.txt
- Thin, duplicated, or auto-generated content flagged by Helpful Content systems
- Pages with zero internal links (orphans), which Google may not trust enough to index
- HTTP errors (4xx/5xx) returned at crawl time
- Slow Time to First Byte, where some pages time out before the indexing pipeline finishes
Index Coverage: The 90% Problem
Google crawls far more than it indexes. Research consistently shows that roughly 90% of crawled content is filtered out before reaching the index. This filtering happens across multiple quality layers: Panda (thin content), Helpful Content (low-value, unhelpful to readers), and algorithmic duplication filters.
Getting crawled is not enough. Getting indexed means passing every quality threshold. This is why content architecture, EEAT signals, and structured data matter from the very first page you publish.
Stage 3: Ranking (The Relevance Layer)
Ranking is where a search engine decides which indexed pages to show for a given query, and in what order. Google's ranking system is not a single algorithm. It's a stack of layered systems that work in sequence.
The 8-Layer Ranking Architecture
The Ranking Stack: How Google Scores Pages
| Layer | System / Signal | What It Does |
|---|---|---|
| 1. Relevance | TF-IDF, BM25, Phrase-Based Indexing | Matches query tokens to indexed content |
| 2. Semantic | Hummingbird, BERT, MUM | Understands query intent and entity meaning |
| 3. Neural | RankBrain, Neural Matching | Handles never-seen queries via ML embeddings |
| 4. Authority | PageRank, Hilltop, Link Graph | Scores domain and page authority via links |
| 5. Quality | Panda, Helpful Content, E-E-A-T | Filters low-quality, thin, unhelpful content |
| 6. UX Signals | Core Web Vitals, Mobile-friendliness | Rewards fast, usable, accessible pages |
| 7. Freshness | Query Deserves Freshness (QDF) | Boosts recent content for time-sensitive queries |
| 8. Personalization | Location, search history, device | Adjusts results per user context |
PageRank and Link Authority
PageRank is Google's foundational algorithm, named after co-founder Larry Page. It scores each page based on the quantity and quality of links pointing to it. A link from a trusted, authoritative page passes more "link equity" than a link from a low-quality page. This principle still governs a significant portion of Google's ranking decisions in 2026.
Two factors have shifted how PageRank operates:
- Reasonable Surfer Model: Google weights links by their position and likelihood of being clicked. A link in the main body content passes more equity than a footer link. This is why internal link placement matters.
- Topical relevance: Links from topically adjacent sites now pass more value than links from unrelated high-authority domains. A backlink from a leading SEO blog is worth more to an SEO agency than a link from a popular cooking site.
Hummingbird, BERT, and MUM: Semantic Understanding
Three algorithm updates fundamentally changed how Google reads content:
- Hummingbird (2013): Moved Google from keyword matching to understanding the full meaning of a query. It enabled conversational search like 'restaurants open near me at 10pm' without breaking it into individual keywords.
- BERT (2019): Applied transformer neural networks to understand word context. The word 'bank' in 'river bank fishing' means something different from 'bank' in 'bank loan rates.' BERT resolves this at query time and at indexing time.
- MUM (2021+): Multimodal Understanding Model. Processes text, images, and video across 75+ languages simultaneously. Powers complex multi-step queries and AI-generated responses.
These systems mean keyword stuffing has been irrelevant for years. Google ranks content that covers a topic comprehensively and accurately, not content that repeats a target phrase the most times.

E-E-A-T: The Quality Framework
Google's E-E-A-T framework, which stands for Experience, Expertise, Authoritativeness, and Trustworthiness, is the quality-rater standard that shapes how algorithms assess content credibility. It's most critical in YMYL (Your Money or Your Life) niches: health, finance, legal, and safety topics.
| Signal | What It Means | How to Build It |
|---|---|---|
| Experience | Author has first-hand involvement | First-person examples, case data, real results |
| Expertise | Demonstrated domain knowledge | Author credentials, deep technical accuracy |
| Authoritativeness | Recognized by peers and other sources | Backlinks, brand mentions, press coverage |
| Trustworthiness | Transparent, accurate, secure | HTTPS, clear authorship, sourced claims |
Core Web Vitals: The UX Ranking Signal
Google's Core Web Vitals measure real-user experience. They became official ranking signals in 2021 and remain active today:
- LCP (Largest Contentful Paint): Time until the largest visible element loads. Target: under 2.5 seconds.
- INP (Interaction to Next Paint): Replaced FID in 2024. Measures responsiveness to user interactions. Target: under 200ms.
- CLS (Cumulative Layout Shift): Measures visual stability. Pages that jump around as they load score poorly. Target: under 0.1.
Core Web Vitals rarely cause dramatic ranking drops on their own. But they act as a tiebreaker when two pages are otherwise equal, and they correlate strongly with user engagement, which feeds back into ranking signals.
Freshness: Query Deserves Freshness (QDF)
Not every query deserves a recent result. A search for 'how does gravity work' does not need a 2026 article; Newton's laws haven't changed. But 'Google algorithm update May 2026' absolutely requires fresh content.
Google's QDF (Query Deserves Freshness) system detects when a spike in search activity around a topic signals that fresh content should be boosted. For news, trending topics, recent events, and time-stamped queries ('best smartphones 2026'), freshness is a significant ranking factor. For evergreen informational content, authority and depth outweigh recency.
Word Sense Disambiguation (WSD) and Why It Matters
One of the most underappreciated mechanisms in modern search ranking is Word Sense Disambiguation (WSD), the process by which a search engine determines which meaning of an ambiguous word applies to a given page.
Take the word 'mercury': it can refer to the planet, the element, the Roman god, the car brand, or the music artist Freddie Mercury. Google's WSD systems analyze the full context of surrounding words, entities, and document structure to determine which sense your page covers, then match it to queries in the same sense.
For SEO, this means topical consistency matters. A page about 'mercury' that mixes planetary and chemical contexts confuses the disambiguation system. Pages that stay semantically consistent, with entities, vocabulary, and context all aligning to one sense, are easier to classify and more likely to rank for the intended query cluster.
Stage 4: SERP Serving (The Presentation Layer)
Once ranking completes, Google assembles the Search Engine Results Page (SERP). In 2026, a SERP is not just ten blue links. It's a dynamic, query-specific assembly of content types, each triggered by different signals.
SERP Features and What Triggers Them
| SERP Feature | Triggered By | Optimization Target |
|---|---|---|
| Featured Snippet | Know-simple queries with clear answers | 40-60 word direct answer after H2 |
| People Also Ask (PAA) | Informational queries with sub-questions | FAQ schema + question-format H3s |
| Knowledge Panel | Named entity searches (brand, person, place) | Organization schema + sameAs + Wikidata |
| AI Overview | Complex informational + research queries | Passage-level direct answers + E-E-A-T |
| Image Pack | Visual queries (products, places, how-tos) | Descriptive alt text + image schema |
| Video Carousel | Tutorial, how-to, review queries | VideoObject schema + transcript indexing |
| Local Pack | Near-me, city-specific queries | Google Business Profile + LocalBusiness schema |
| Shopping Carousel | Product queries | Product schema + Google Merchant Center |
Structured Data: The Machine-Readable Layer
Structured data specifically JSON-LD schema markup tells search engines exactly what your content means without requiring inference. A page about a recipe that includes Recipe schema gives Google the ingredient list, cook time, and calorie count in a format it can display directly in the SERP.
For informational content, the highest-value schema types are:
- Article schema: declares the content as a news article, blog post, or technical guide with author and publication date.
- FAQPage schema: makes Q/A sections eligible for direct PAA inclusion.
- HowTo schema: enables step-by-step rich results for tutorial content.
- Organization schema: establishes brand entity grounding with sameAs links to Wikidata, LinkedIn, and official profiles.
- Speakable schema: marks passages suitable for voice search and AI engine quoting.
- BreadcrumbList schema: communicates site hierarchy to Google and powers breadcrumb rich results.
Stage 5: AI Synthesis & The Generative Layer
In 2026, a fifth stage sits above traditional SERP serving for millions of queries: AI-generated synthesis. Google AI Overviews, ChatGPT Search, Perplexity, and Gemini all retrieve passages from indexed content and generate a direct answer then cite the sources they used.
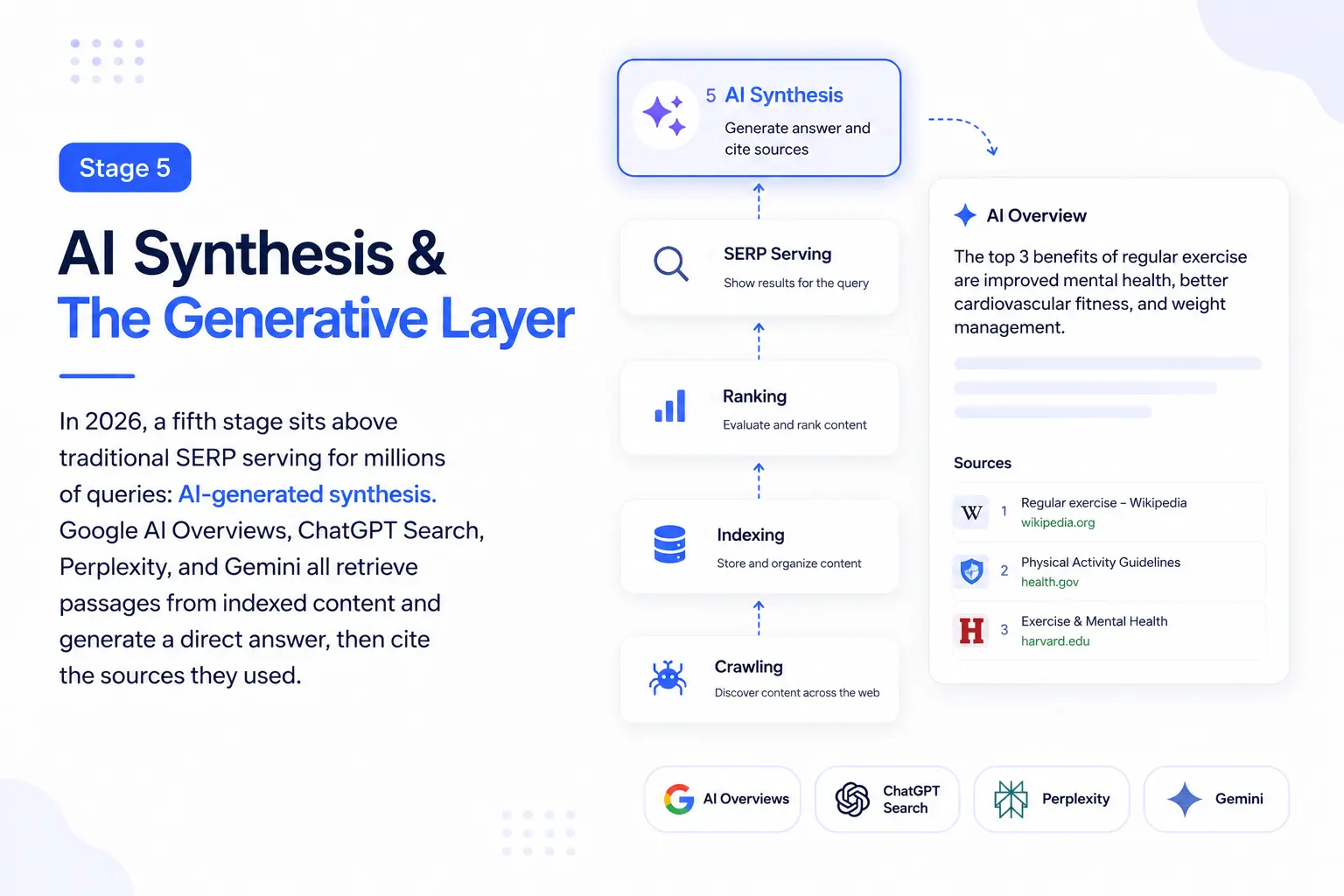
AI Synthesis: RAG Data Pipeline
How AI Overviews Select Sources
Google AI Overviews don't rank sources the same way the organic algorithm does. They apply Retrieval-Augmented Generation (RAG): retrieve relevant passages from already-indexed, already-ranked content, then synthesize an answer and cite the sources of those passages.
The implication: to appear in AI Overviews, you must first rank organically. But ranking alone is not enough your content must contain retrievable passages: self-contained, factually dense, directly answering the query at the passage level.
Pages with high E-E-A-T scores, structured data markup, and passage-level direct answers appear in AI Overviews at a dramatically higher rate than pages that lack these signals.
Citation Patterns by AI Engine
| AI Engine | Preferred Source Types | Optimization Focus |
|---|---|---|
| Google AI Overviews | Already top-ranking organic results + E-E-A-T-strong sites + schema markup | Organic rankings + structured data + passage structure |
| ChatGPT Search | Wikipedia (~48% of citations), educational, government, news | Encyclopedic tone + cited sources + Wikidata grounding |
| Perplexity | Reddit (~47% of citations), fresh blogs, forums (90-day window) | Recent content + first-hand experience + conversational tone |
| Gemini | Academic sources, technical depth, well-cited references | Authority citations + technical accuracy + structured markup |
Passage Engineering for AI Citation
Getting cited by AI engines requires a specific content architecture we call passage engineering:
- Direct-answer passage in the first 100 words: 40-60 words, self-contained, includes the entity and the answer.
- Self-contained H2 sections: each section reads independently without depending on context above it.
- Chunk length 80-150 words per section: long enough to be substantive, short enough to be retrievable.
- Factual density: numbers, dates, named entities, and citations in every passage.
- Citation hooks: link to Wikipedia, official standards, and peer-reviewed sources.
- Speakable schema: marks the passages most suitable for AI quoting.
Key Stat: Pew Research found in 2025 that users who saw a Google AI Overview clicked a traditional search result in only 8% of visits, vs. 15% without an AI Overview. This means appearing IN the AI Overview is now more valuable than ranking #1 below it.
How Search Engines Use Entities and the Knowledge Graph
Modern search engines don't just index words. They index things. The shift from keyword-based indexing to entity-based indexing is the single biggest change in how search has worked over the past decade.
The Knowledge Graph Entity Model
What Is an Entity in SEO?
An entity is a real-world thing that can be uniquely identified and distinguished from other things: a person, an organization, a place, a product, a concept. Google's Knowledge Graph stores entities and the relationships between them.
When you search 'who founded Microsoft', Google doesn't scan for pages with the words 'founded' and 'Microsoft.' It looks up the entity Microsoft (organization), traverses the relationship 'foundedBy', and returns the entity Bill Gates (person). The answer comes from the Knowledge Graph, not from a specific page.
Entity-Attribute-Value (EAV) Model
Every entity in the Knowledge Graph is described by attribute-value pairs. This is the EAV model:
- Entity: A1 Technovation
- Attribute: businessType | Value: Digital Marketing Agency
- Attribute: founded | Value: 2018
- Attribute: location | Value: Dhaka, Bangladesh
- Attribute: services | Value: SEO, AEO, GEO, PPC, Web Development
Content that explicitly covers an entity's key attributes in accurate, machine-readable language trains Google to associate those attribute-value pairs with your brand entity. This builds Knowledge Graph representation and increases AI citation likelihood.
Named Entity Recognition (NER) and Salience
During indexing, Google's NLP systems run Named Entity Recognition (NER) on every page. NER identifies and classifies entities in the text: people, organizations, locations, products, events, dates, quantities. Each entity is then assigned a salience score, a measure of how central it is to the document.
A page that mentions 'SEO' 40 times has high entity salience for the SEO entity. But a page that mentions 'SEO', discusses its sub-entities (on-page SEO, technical SEO, link building), covers its attributes (keyword research, crawl optimization, EEAT), and links to authoritative SEO sources has dramatically higher topical depth. It scores proportionally higher in semantic ranking.
How to Optimize Your Content for Every Stage of Search
Understanding how search engines work is the foundation. Applying that understanding to your content and site architecture is how you turn it into rankings, citations, and revenue.
Crawl Optimization Checklist
- Submit an XML sitemap to Google Search Console, split by section for large sites.
- Keep important pages within 3 clicks of the homepage.
- Fix all redirect chains to a maximum of 1 hop.
- Remove noindex tags from any page you want ranked.
- Use a consistent internal linking structure to flow crawl equity to priority pages.
- Resolve robots.txt errors that block crawling of CSS/JS files needed for rendering.
- Improve TTFB below 200ms. Server response time directly affects crawl rate.
Index Optimization Checklist
- Every page you want indexed must offer unique, substantive value, not a thin variation of another page.
- Use canonical tags correctly to consolidate duplicate URLs.
- Add structured data (JSON-LD) to every page. It lowers indexing cost and improves entity classification.
- Build internal links to orphan pages. They need equity to earn trust for indexing.
- Avoid faceted navigation creating millions of low-value URL variants.
- Run a monthly index coverage audit in GSC to find excluded pages.
Ranking Optimization Checklist
- Match content depth to search intent. Informational queries need depth; transactional queries need conversion clarity.
- Build topical authority through comprehensive topic coverage, not isolated page optimization.
- Earn backlinks from topically relevant, trusted domains in your niche.
- Optimize Core Web Vitals: LCP under 2.5s, INP under 200ms, CLS under 0.1.
- Add author schema with credentials and sameAs links to establish EEAT signals.
- Use predicate-specific language: 'requires', 'enables', 'restricts' vs. generic verbs like 'is' and 'has'.
- Refresh content before it decays. Set a schedule based on content type.
AEO and LLM Citation Checklist
- Write a 40-60 word direct-answer passage in the first 100 words of every priority page.
- Structure every H2 section to be self-contained and independently readable.
- Add FAQPage schema to every article that contains Q/A blocks.
- Link out to authoritative sources (Wikipedia, Google Search Central, peer-reviewed papers).
- Add Speakable schema to mark passages suitable for voice/AI quoting.
- Add a /llms.txt file at your site root declaring your key entities, topics, and preferred citation format.
- Do not block AI crawlers (GPTBot, PerplexityBot, ClaudeBot) in robots.txt if you want AI citations.
How Different Search Engines Compare
Google dominates with ~90% of global search market share. But Bing, DuckDuckGo, Perplexity, and ChatGPT Search each have meaningful audiences, and they don't all rank the same way.
| Search Engine | Market Share | Ranking Approach | Key Differentiator | Optimization Priority |
|---|---|---|---|---|
| ~90% | Multi-layer ML + semantic | Entity understanding, E-E-A-T, AI Overviews | Topical authority + structured data | |
| Bing / Copilot | ~3-4% | Similar to Google + Copilot AI layer | Powers ChatGPT Search via Bing index | Same SEO principles + Bing Webmaster Tools |
| DuckDuckGo | ~0.6% | Bing index + privacy-first | No personalization, no tracking | Standard SEO; Bing signals apply |
| Perplexity | Growing rapidly | RAG-based answer generation | Favors fresh, Reddit-adjacent content | Recency + conversational writing |
| ChatGPT Search | Growing rapidly | Bing index + GPT synthesis | Wikipedia + educational sources favored | Encyclopedic depth + Wikidata grounding |
Common Misconceptions About How Search Engines Work
Misconception 1: More Keywords = Better Rankings
Keyword density as a ranking factor effectively died with Hummingbird in 2013. Google's semantic understanding means a page about 'home espresso machines' can rank for 'best coffee maker for small apartments' without the phrase ever appearing, because the entity graph connects these concepts. Over-optimization still triggers spam filters. Write for humans first; semantic coverage handles the rest.
Misconception 2: Google Uses Meta Keywords
Google officially stopped using the meta keywords tag in 2009. It has zero ranking influence. Focus on your meta title (60 chars, keyword near front) and meta description (160 chars, benefit-driven, includes keyword). These influence click-through rate, which does affect rankings indirectly.
Misconception 3: Social Signals Are a Ranking Factor
Social shares, likes, and followers do not directly influence Google rankings. Google cannot reliably crawl or authenticate social data. Social signals do help indirectly: viral content earns backlinks, increases brand search volume, and drives traffic, all of which feed real ranking signals.
Misconception 4: Backlinks Are the Only Authority Signal
Links remain the most powerful authority signal. But brand mentions without links (also called implied links or co-citations), author entity signals, consistent NAP (Name, Address, Phone) data for local businesses, structured data, and Knowledge Graph representation all contribute to how Google models your authority.
Misconception 5: Once You Rank, You Stay Ranked
Rankings are not permanent. Content decays: statistics become outdated, competitors publish better content, algorithms update. We track refresh cadences for every content type: stats-heavy posts refresh every 3 months, evergreen how-tos every 6-12 months, and comparison pages every 6 months. Ranking without a maintenance plan is a short-term win that erodes quietly.
How A1 Technovation Applies This to Client Campaigns
Every client engagement we run at A1 Technovation starts with this framework, not with keyword research, not with link building. We map the full entity model first, then build site architecture around topical coverage, then optimize for both organic ranking and AI citation simultaneously.
Our approach, built across 150+ global clients since 2018:
- Entity audit: map every entity your site covers and compare against Knowledge Graph representation.
- Crawl and index audit: identify which pages are wasting crawl budget and which are wrongly excluded.
- Topical map: plan content that covers every attribute of your central entity, published satellite-first.
- Passage engineering: structure every priority page for passage-level retrieval by AI engines.
- Schema deployment: JSON-LD on every page, FAQPage on every article, Organization schema globally.
- Link authority: earn backlinks from topically adjacent, trusted domains, not link farms.
- Measurement: track coverage %, ranking velocity, and AI citation appearances monthly.
We rank on Google AND get cited by AI engines. If your current SEO strategy doesn't include both, you're leaving visibility on the table. Talk to our team at a1technovation.com/contact.
Frequently Asked Questions
How long does it take a search engine to index a new page?
Google can index a new page within hours for high-authority domains with active sitemaps and frequent crawling. For newer or less authoritative sites, indexing typically takes 1-4 weeks. Submitting the URL through Google Search Console's URL Inspection tool speeds this up considerably.
Does Google index JavaScript-rendered content?
Yes, but with a delay. Google operates a two-wave indexing system: HTML is indexed immediately, then JavaScript-rendered content is processed by a secondary rendering queue that can lag days to weeks behind. Critical SEO content (headings, internal links, body text) should never depend exclusively on JavaScript to render.
How many ranking factors does Google use?
Google has confirmed it uses "hundreds" of signals. The widely cited figure of 200+ ranking factors comes from Google's own statements and patent analysis. In practice, the most impactful signals in 2026 are: content quality and E-E-A-T, relevance to search intent, backlink authority and topical relevance, Core Web Vitals, and structured data presence.
What is the difference between crawling and indexing?
Crawling is the discovery and download stage: Googlebot fetches the raw HTML of a page. Indexing is the analysis and storage stage: the fetched content is processed, entities are extracted, quality is assessed, and qualified pages are written to the search index. A page can be crawled but not indexed if it fails quality thresholds.
How do AI Overviews decide which sources to cite?
Google AI Overviews use Retrieval-Augmented Generation (RAG). They retrieve self-contained passages from already-ranking organic results biasing toward pages with high E-E-A-T scores, structured data markup, and passage-level direct answers. The selection is not random: passages that directly answer the query at the sentence level are preferentially retrieved.
Does page speed affect search engine rankings?
Yes, through Core Web Vitals, which are confirmed ranking signals. LCP (load time for the largest element) targets under 2.5 seconds. INP (responsiveness) targets under 200ms. CLS (layout stability) targets under 0.1. Beyond direct ranking impact, fast pages reduce bounce rate and improve engagement metrics both of which correlate with better long-term rankings.
Can I rank without backlinks?
Yes, for lower-competition queries. For high-competition commercial queries, backlinks remain near-essential. The path to ranking without links is topical authority: exhaustive coverage of a narrow niche, published consistently, with strong on-page entity signals and structured data. This strategy works best for new sites targeting informational queries in underserved niches.
What is passage indexing and how does it affect SEO?
Passage indexing means Google can rank a specific section of a long page for a query not just the overall page. Announced in 2020 and now standard, it creates ranking opportunities for every H2 section on your page. Each section should stand alone, open with a direct answer, and cover one specific sub-entity or attribute. Think of each H2 as its own miniature ranking target.
Go from search theory to execution
These companion guides move from search mechanics into optimization, technical implementation, and AI-era visibility.
Turn Algorithm Knowledge Into Revenue
We rank on Google AND get cited by AI engines. If your current SEO strategy doesn't include both, you're leaving visibility on the table.
Talk to our team →